和金钱相关的系统,都很有挑战性,是因为在这里,一切都很严肃
----by Someone you don’t know
伴随着用户群积累,社区的壮大,还有来自投资人对变现渴望的压力,似乎最容易想到的变现途径就是“我们也卖点东西吧”,如果直接给淘宝链接,会显得逼格太低,购买别人的系统,钱不少花,最后为了适应自己的需求,也要做相当多的工作,所以,越来越多不同的App里有了商城。当然根据不同的业务需求,复杂度也大相径庭。
笔者还没有能力“大话电商系统”,只是把实际开发过程中遇到过的逻辑陷阱阐述一下,并逐级优化,给出一个我认为的比较稳妥的方案,电商系统,博大精深,我提出的问题都比较小,并且很可能属于新手的坑。也欢迎读文章读你提出更多问题,或者更优方案。
问题1. 一个小保证,确保订单不会被恶意修改
看了文字,标题肯定觉得懵逼了。举个例子吧,例如用户A的订单已支付,用户B却可能将它变成申请退款。
怎么可能?
如果这个系统存在漏洞,并且B是一个愿意尝试的程序员!
之前Review过一些团队小伙伴的代码,简单来说,修改订单状态被描述成如下流程:
1. 登陆验证等
2. 通过POST接受到Client传过来的OrderID
3. 修改订单
那么问题出现了,如果用户B利用技术手段发送了A订单的ID,会怎么样?如果系统没有做充分的校验工作,那么对不起,一个登录用户可以尝试所有数字,把所有订单都搞乱。
当然这是一件很简单的例子,当然优化的方案有很多,最简单的方案应该就是先获取订单。
这里获取订单同时增加了订单所有者的约束,以防止恶意更改别人的订单。
如果不涉及到其他的关于订单操作,也可以简简单单在更新的时候,确保订单所有者。
问题1. 扣库溢出问题(超卖问题)
之前有个朋友遇到过这个问题,他说他们销售的某些商品比较热销,导致很多人去哄抢,在停止哄抢的时候,却发现商品库存是负数。这应该是典型的超卖了吧。
如果没有过多的思考,扣库存的过程很容易写成大概类似如下这个样子:
直接在流程语句中判断库存是否为0,若>0就可以买。
如果用户量很小,这段代码应该没有问题,如果用户变多,同一时刻有多个(Tread)同时运行这段代码,那么情况就很糟糕了,因为这段代码并不是线程安全的。
有3种解决方案1、表锁定;2、文件锁;3、sql语句验证法;具体解决方案参看:http://www.xuduowei.com/archives/500
参考:https://blog.csdn.net/hopeztm/article/details/51704583
==========================
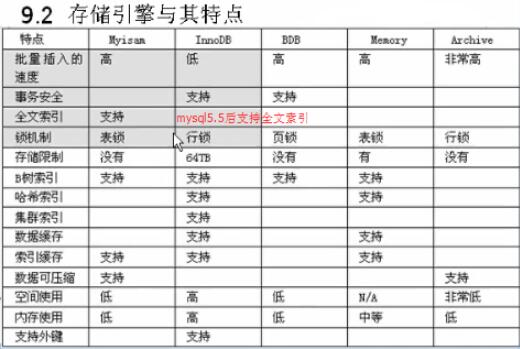
数据库使用何种存储引擎取决于业务,读多一些并且不需要经常对表进行该的这种Myisam足够了!
经常写,如订单这种,需要多表关联的数据,用到了事务处理,这种只能用Innodb。
归结一下为什么InnoDB比MyIsam更流行:
1. InnoDB经过长时间的发展和优化,性能已经非常好了,绝大部分场景都能有更好的性能。最主要的原因就是InnoDB是 行锁;Myisam是 表锁;
只有完全插入型或者读取型的表用Myisam会略微快一点。
2. 事务在关系型数据库中非常重要的一个特性,很多实用场景都需要用到事务特性,而InnoDB支持但MyIsam不支持。
其他的存储引擎使用场景都不太多,偶尔会用到Memory去做热表。
- InnoDB是行锁,Myisam是表锁
- InnoDB 支持事务
- InnoDB 不断在升级优化
- 时至今日,不用想了,myisam和innodb比没有任何优势。
提示:有一些开源商城并没有用到innodb,比如:ecshop,opencart 中购物车,订单表并没有使用到事务。
EC没有使用事务,比如余额付款提交订单,它的流程:
1.商品加入购物车
2.生成订单
3.扣减余额进行付款记录
4.更新订单状态
那么,如果某个用户在3这一步的mysql中断了(比如某个瞬间服务器停电了),它就会付了款订单却是未付款的尴尬状态.
…
另外,EC被收购后就没有更新,所以一直都是这种老古董状态了.好在商派现在的一些如SHOPNC之类的产品有进行了事务处理.