解决办法:
打开php.ini并找到如下一行
;always_populate_raw_post_data = -1
去掉前面的注释即可
最后记得重启服务器。

徐多蔚APP开发,合肥物联网项目开发,合肥网络开发,合肥项目高端定制,企业oa开发,合肥小程序开发,合肥公众号开发,合肥网络安防 – 徐多蔚 xuduowei
联系方式[微信]:徐多蔚15309695130 感恩有您的陪伴,我们用心服务每一位客户 – 徐多蔚 xuduowei
解决办法:
打开php.ini并找到如下一行
;always_populate_raw_post_data = -1
去掉前面的注释即可
最后记得重启服务器。
function ac(){
$obj=new \app\admin888\model\ProductsModel;
$b=1;//标志成功的状态,一般失败,就修改其为0
for($j=0;$j<=10;$j++){
for($i=0;$i<=5;$i++){
$obj->db->query("insert into cbd_products_attr_guige set uid=5");
if($i==4){//一旦与遇错
//Db::rollback();//可以省略,在try那里一起操作
$b=0;//设置出错标志
break;//终止本次循环,不可少。
}
}
if(!$b){//外层循环中判断里面有错误,则外层也终止。数据库回滚。
//Db::rollback();在try那里一起操作
break;//终止本次循环,不可少。
}
}
//echo 1;
return $b;
}
function trya(){
// 启动事务
Db::startTrans();
try{
$b=$this->ac();
if($b){
Db::commit();
return 1;
}else{
Db::rollback();
return 0;
}
} catch (\Exception $e) {
//echo 0;
// 回滚事务
Db::rollback();
return 2;
}
}
//测试
function cs(){
echo $this->trya();
}
问题描述:使用TP框架做项目时,在启用REWRITE的伪静态功能的时候,首页可以访问,但是访问其它页面的时候,就提示:“No input file specified.”
原因在于使用的PHP5.6是fast_cgi模式,而在某些情况下,不能正确识别path_info所造成的错误
默认的.htaccess里面的规则:
IfModule mod_rewrite.c>
Options +FollowSymlinks
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*)$ index.php/$1 [QSA,PT,L]
</IfModule>“No input file specified.”,是没有得到有效的文件路径造成的。
修改后的伪静态规则,如下:
IfModule mod_rewrite.c>
Options +FollowSymlinks
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*)$ index.php?/$1 [QSA,PT,L]
</IfModule>仅仅就是在正则结果“/$1”前面多加了一个“?”号,问题也就随之解决了。
虽然我认为讨论技术问题时,宣扬“自己的系统实际表现有多牛(所以别人也一定要这么做)”不是什么好的论调……但我必须认同一点:这个问题的权衡还真就不是从性能上考虑的。时间戳和字面时间的互转只是简单的计算,所消耗的资源远远达不到引发问题的地步。
使用时间戳的唯一考虑是:你的应用是否涉及多时区,时间数据是否和时区相关。如果回答“是”,那么就必须使用时间戳,没有任何第二方案。
只有时间戳表示的时间是准确、恒定的,就连时间+日期+时区也不行——时区这玩意儿可不是恒定不变的……
其余的都不是什么重要的考虑,自己喜欢就行。
一般认为坚持使用时间戳总是好的,在程序设计中只会提供便利,不会引入坏处。至于查看数据时暴露时间戳原值,那是显示环节的不完备(或故意设计),而不是用时间戳用错了,切勿张冠李戴抹黑好东西。
日期的字符串-时间互转、计算、比较及时区转换,请使用后台语言中提供的相关类,不自己造轮子就可以。
可以略微注意:2038年问题的陷阱。对于MySQL而言,如果存时间戳请使用bigint,而尽量不要使用int;若存时间是字符串型的,建议使用TIMESTAMP或者DATETIME。
TIMESTAMP与DATETIME2者的区别:
TIMESTAMP和DATETIME的相同点:
1> 两者都可用来表示YYYY-MM-DD HH:MM:SS[.fraction]类型的日期。
TIMESTAMP和DATETIME的不同点:
1> 两者的存储方式不一样
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。
而对于DATETIME,不做任何改变,基本上是原样输入和输出。
2> 两者所能存储的时间范围不一样
timestamp所能存储的时间范围为:'1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999'。
datetime所能存储的时间范围为:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'。
总结:TIMESTAMP和DATETIME除了存储范围和存储方式不一样,没有太大区别。当然,对于跨时区的业务,TIMESTAMP更为合适。
https://www.cnblogs.com/mxwz/p/7520309.html
转载:http://www.360doc.com/content/16/0614/06/9200790_567583079.shtml
编写整理:徐多蔚
创建数据库:
#nihaoma就是我们的数据库名称
create database nihaoma;
#删除库
drop database nihaoma;
#查看所有的数据库
show databases;
#设置当前要操作的数据库
use nihaoma;
#列表查看指定库下的所有的表
show tables;
#若没表,我们可以演示创建;
CREATE TABLE `obj_users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) NOT NULL,
`password` char(32) NOT NULL DEFAULT '',
`addtime` datetime DEFAULT NULL COMMENT '添加时间',
`updatetime` datetime DEFAULT NULL,
`gid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `id` (`id`),
UNIQUE KEY `username` (`username`)
) ENGINE=MyISAM AUTO_INCREMENT=56 DEFAULT CHARSET=utf8 COMMENT='用户表';
#命令行下查看表结构
desc obj_users;
#增加字段指令 tc004_tp5为数据库名,obj_users为名
ALTER TABLE `tc004_tp5`.`obj_users`
ADD COLUMN `cs4` varchar(255) NULL DEFAULT NULL COMMENT '测试';
#注意cmd命令下若输入中文的备注,有可能会出现乱码。
#修改字段(cs4中的备注为csssss)指令
ALTER TABLE `tc004_tp5`.`obj_users`
CHANGE COLUMN `cs4` `cs4` varchar(255) NULL DEFAULT NULL COMMENT 'csssss';
#删除字段cs4指令
ALTER TABLE `tc004_tp5`.`obj_users`
DROP COLUMN `cs4`;
#删除表
drop table obj_users;
#增,删,改,查sql语句这里省略。
……
1,存在方式:
临时存在于 服务器内存中
视图 无存在形式
2, 生命周期:
临时表 Sql服务关闭就消失
视图 你不删它就不会消失
3,用途
临时表 经常作为 中间转接层
视图 作为物理表的窗口
4,效率
临时表因为在缓存中,所以执行效率比较高
视图 效率一般,但是节省I/O操作,节约资源
5,在存储过程使用时:
临时表,效率很高{可能是数据量少,再加上临时表是在缓存中,所以执行效率高}
视图 一般
CREATE TEMPORARY TABLE tmp_table SELECT * FROM table_name;视图功能,只是把多个表,按照自已的需求,东一块西一块,逻辑拼在一起,形成一个逻辑表。调用的时候直接操作这个逻辑表视图就可以了,其它分析解释的操作就交给mysql引擎去处理,最终查询还是要经原来的物理表的。用视图是不会节省sql执行时间的,反而会增加解析时间,减少效率的。但是视图有视图的优势!
视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。
但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图有很多优点,主要表现在:
1\简化查询
3\定制数据【可以在视图中只开放部分指定的数据】
4\合并分割数据【大数据分表的时候可以用到】视图存放:视图都放在VIEWS表里面:可以用过以下指令查看。
SELECT * FROM `information_schema`.`VIEWS`;
其他参考:https://zhidao.baidu.com/question/2119873937635607147.html?qbl=relate_question_2&word=%B1%ED%CA%D3%CD%BC%20%C4%DC%CC%E1%B8%DFsql%D0%A7%C2%CA%C2%F0

和金钱相关的系统,都很有挑战性,是因为在这里,一切都很严肃
----by Someone you don’t know
伴随着用户群积累,社区的壮大,还有来自投资人对变现渴望的压力,似乎最容易想到的变现途径就是“我们也卖点东西吧”,如果直接给淘宝链接,会显得逼格太低,购买别人的系统,钱不少花,最后为了适应自己的需求,也要做相当多的工作,所以,越来越多不同的App里有了商城。当然根据不同的业务需求,复杂度也大相径庭。
笔者还没有能力“大话电商系统”,只是把实际开发过程中遇到过的逻辑陷阱阐述一下,并逐级优化,给出一个我认为的比较稳妥的方案,电商系统,博大精深,我提出的问题都比较小,并且很可能属于新手的坑。也欢迎读文章读你提出更多问题,或者更优方案。
看了文字,标题肯定觉得懵逼了。举个例子吧,例如用户A的订单已支付,用户B却可能将它变成申请退款。
怎么可能?
如果这个系统存在漏洞,并且B是一个愿意尝试的程序员!
之前Review过一些团队小伙伴的代码,简单来说,修改订单状态被描述成如下流程:
1. 登陆验证等
2. 通过POST接受到Client传过来的OrderID
3. 修改订单
那么问题出现了,如果用户B利用技术手段发送了A订单的ID,会怎么样?如果系统没有做充分的校验工作,那么对不起,一个登录用户可以尝试所有数字,把所有订单都搞乱。
当然这是一件很简单的例子,当然优化的方案有很多,最简单的方案应该就是先获取订单。
这里获取订单同时增加了订单所有者的约束,以防止恶意更改别人的订单。
如果不涉及到其他的关于订单操作,也可以简简单单在更新的时候,确保订单所有者。
之前有个朋友遇到过这个问题,他说他们销售的某些商品比较热销,导致很多人去哄抢,在停止哄抢的时候,却发现商品库存是负数。这应该是典型的超卖了吧。
如果没有过多的思考,扣库存的过程很容易写成大概类似如下这个样子:
直接在流程语句中判断库存是否为0,若>0就可以买。如果用户量很小,这段代码应该没有问题,如果用户变多,同一时刻有多个(Tread)同时运行这段代码,那么情况就很糟糕了,因为这段代码并不是线程安全的。
有3种解决方案1、表锁定;2、文件锁;3、sql语句验证法;具体解决方案参看:http://www.xuduowei.com/archives/500
参考:https://blog.csdn.net/hopeztm/article/details/51704583
==========================
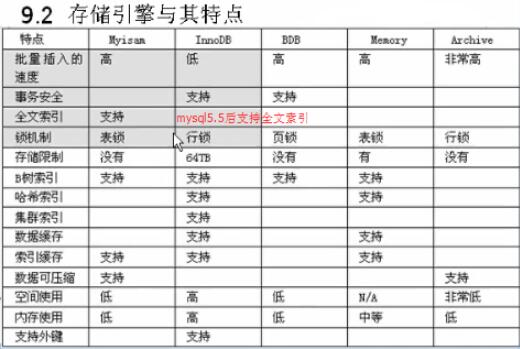
数据库使用何种存储引擎取决于业务,读多一些并且不需要经常对表进行该的这种Myisam足够了!
经常写,如订单这种,需要多表关联的数据,用到了事务处理,这种只能用Innodb。
归结一下为什么InnoDB比MyIsam更流行:
1. InnoDB经过长时间的发展和优化,性能已经非常好了,绝大部分场景都能有更好的性能。最主要的原因就是InnoDB是 行锁;Myisam是 表锁;
只有完全插入型或者读取型的表用Myisam会略微快一点。
2. 事务在关系型数据库中非常重要的一个特性,很多实用场景都需要用到事务特性,而InnoDB支持但MyIsam不支持。
其他的存储引擎使用场景都不太多,偶尔会用到Memory去做热表。
提示:有一些开源商城并没有用到innodb,比如:ecshop,opencart 中购物车,订单表并没有使用到事务。
EC没有使用事务,比如余额付款提交订单,它的流程:
1.商品加入购物车
2.生成订单
3.扣减余额进行付款记录
4.更新订单状态
那么,如果某个用户在3这一步的mysql中断了(比如某个瞬间服务器停电了),它就会付了款订单却是未付款的尴尬状态.
…
另外,EC被收购后就没有更新,所以一直都是这种老古董状态了.好在商派现在的一些如SHOPNC之类的产品有进行了事务处理.
互联网发达的今天,大大小小的网站如雨后春笋,不断出现,但是想要做出一个网站很简单,但是想要做好一个网站,非常非常难,首先:网站做好之后的功能怎么样这都是次要的,主要的是你的网站能承受怎么样的访问量,一个在高压访问下,能承受很高峰值的访问并发才能称得上是一个好的网站,那么作为一个程序员,当你搭建好你的网站之后,你应该怎么测试你的网站并发访问量呢?
接下来要介绍的就是apache的ab命令压测:
-T参数。-T参数。application/x-www-form-urlencoded,默认值为text/plain。ab -help。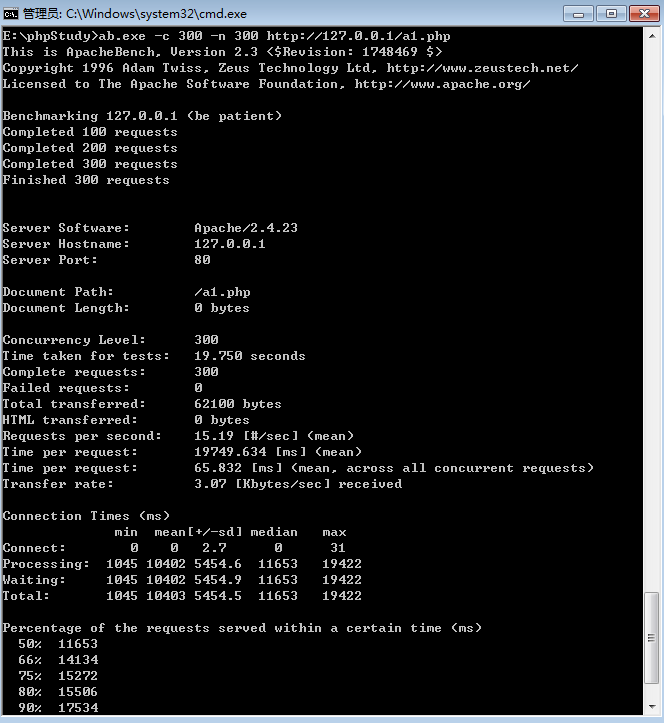

Server Software: Apache/2.4.23(服务器软件名称及版本信息)
Server Hostname: 127.0.0.1(服务器主机名)
Server Port: 80 (服务器端口)
Document Path: /a1.php (供测试的URL路径)
Document Length: 0 bytes (供测试的URL返回的文档大小)
Concurrency Level: 300 (并发数)
Time taken for tests: 19.750 seconds (压力测试消耗的总时间)
Complete requests: 300(压力测试的的总次数)
Failed requests: 0 (失败的请求数)
Total transferred: 62100 bytes (传输的总数据量)
HTML transferred: 0 bytes (HTML文档的总数据量)
Requests per second: 15.19 [#/sec] (mean) (平均每秒的请求数)
Time per request: 19749.634 [ms] (mean) (所有并发用户(这里是300)都请求一次的平均时间)
Time per request: 65.832 [ms] (mean, across all concurrent requests) (单个用户请求一次的平均时间)
Transfer rate: 3.07 [Kbytes/sec] received (传输速率,单位:KB/s)
为什么要优化:
随着实际项目的启动,数据库经过一段时间的运行,最初的数据库设置,会与实际数据库运行性能会有一些差异,这时我们就需要做一个优化调整。
数据库优化这个课题较大,可分为四大类:
》服务器硬件性能:主机,内存;
》网络传输性能
》SQL语句执行性能【软件工程师】
下面列出一些数据库SQL优化方案:
(01)创建表的时候,分配合适的字段类型和大小;
(02)给经常参与条件检索的单个字段或者多个字段加索引,特例中需要唯一性的,记得加唯一索引。
(03)选择最有效率的表名顺序(笔试常考)
数据库的解析器按照从右到左的顺序处理FROM子句中的表名,
FROM子句中写在最后的表将被最先处理,
在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表放在最后,
如果有3个以上的表连接查询,那就需要选择那个被其他表所引用的表放在最后。
例如:查询员工的编号,姓名,工资,工资等级,部门名
select emp.empno,emp.ename,emp.sal,salgrade.grade,dept.dname
from salgrade,dept,emp
where (emp.deptno = dept.deptno) and (emp.sal between salgrade.losal and
salgrade.hisal)
1)如果三个表是完全无关系的话,将记录和列名最少的表,写在最后,然后依次类推
2)如果三个表是有关系的话,将引用最多的表,放在最后,然后依次类推
(04)WHERE子句中的连接顺序(笔试常考)
数据库采用自右而左的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之左,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的之右。
例如:查询员工的编号,姓名,工资,部门名
select emp.empno,emp.ename,emp.sal,dept.dname
from emp,dept
where (emp.deptno = dept.deptno) and (emp.sal > 1500)
(05)SELECT子句中避免使用*号
数据库在解析的过程中,会将*依次转换成所有的列名,这个工作是通过查询数据字典完成的,这
意味着将耗费更多的时间
select empno,ename from emp;
(06)用TRUNCATE替代DELETE
(07)用WHERE子句替换HAVING子句
WHERE先执行,HAVING后执行
(08)多使用内部函数提高SQL效率
(9)使用表的别名和列的别名
使用表的别名
salgrade s
使用列的别名
ename e
(10)尽可能少使用子查询,可使用left join代替