
- 我今天特地试验了一下两者的性能
php自带的排序函数 100000的数据 排序 平均耗时0.068s microtime()//php自带排序sort()耗时:0.12000608444214- 返回当前 Unix 时间戳的微秒数。
-
for ($i = 0; $i<100000;$i++){ $arr[] = rand(0,10000); } $t1 = microtime(true); sort($arr); $t2 = microtime(true); echo "php自带排序sort()耗时:".($t2-$t1);自己写的快速排序 平均耗时1.0s
//快速排序耗时:1.7631008625031
for ($i = 0; $i<100000;$i++){ $arr[] = rand(0,100000); } $t1 = microtime(true); $returnAr = quickSort($arr); $t2 = microtime(true); echo "快速排序耗时:".($t2-$t1); //快速排序 function quickSort($arr) { //先判断是否需要继续进行 $length = count($arr); if($length <= 1) { return $arr; } //选择第一个元素作为基准 $base_num = $arr[0]; //遍历除了标尺外的所有元素,按照大小关系放入两个数组内 //初始化两个数组 $left_array = array(); //小于基准的 $right_array = array(); //大于基准的 for($i=1; $i<$length; $i++) { if($base_num > $arr[$i]) { //放入左边数组 $left_array[] = $arr[$i]; } else { //放入右边 $right_array[] = $arr[$i]; } } //再分别对左边和右边的数组进行相同的排序处理方式递归调用这个函数 $left_array = quickSort($left_array); $right_array = quickSort($right_array); //合并 return array_merge($left_array, array($base_num), $right_array); }明显是php自带的函数排序速度快很多。
但重点是,为什么还有那么多问题是问 如何用php实现快速排序等算法?
php四排序-冒泡排序
算法和数据结构是一个编程工作人员的内功,技术牛不牛,一般都会看这两点。作为php程序员, 提升技能当然也得学习算法。
下面介绍四种入门级排序算法: 冒泡排序、选择排序、插入排序、快速排序。
一、冒泡排序
原理:对一组数据,比较相邻数据的大小,将值小数据在前面,值大的数据放在后面。 (以下都是升序排列,即从小到大排列)
举例说明: $arr = array(6, 3, 8, 2, 9, 1);
$arr 有6个数据,按照两两比较大小如下,注意 比较轮数 和 每轮比较次数
第一轮排序:
第一次比较 6和3比较 结果:3 6 8 2 9 1
第二次比较 6和8比较 结果:3 6 8 2 9 1
第三次比较 8和2比较 结果:3 6 2 8 9 1
第四次比较 8和9比较 结果:3 6 2 8 9 1
第五次比较 9和1比较 结果:3 6 2 8 1 9
第一轮比较总结:1.排序第1轮、比较5次,没有获得从小到大的排序 2.因为每次比较都是大数往后靠,所以比较完成后,可以确定大数排在最后(9 已经冒泡冒出来了,下轮比较可以不用比较了 )
第二轮排序:
第一次比较 3和6比较 结果:3 6 2 8 1 9
第二次比较 6和2比较 结果:3 2 6 8 1 9
第三次比较 6和8比较 结果:3 2 6 8 1 9
第四次比较 8和1比较 结果:3 2 6 1 8 9
第二轮比较总结:1.排序第2轮、比较4次,没有获得从小到大的排序 2.冒泡出了 8,下轮不用比较8 了
第三轮排序:
第一次比较 3和2比较 结果:2 3 6 1 8 9
第二次比较 3和6比较 结果:2 3 6 1 8 9
第三次比较 6和1比较 结果:2 3 1 6 8 9
第三轮比较总结:1.排序第3轮、比较3次,没有获得从小到大的排序 2.冒泡出了 6,下轮不用比较6 了
第四轮排序:
第一次比较 2和3比较 结果:2 3 1 6 8 9
第二次比较 3和1比较 结果:2 1 3 6 8 9
第四轮比较总结:1.排序第4轮、比较2次,没有获得从小到大的排序 2.冒泡出了 3,下轮不用比较3 了
第五轮排序:
第一次比较 2和1比较 结果:1 2 3 6 8 9
第五轮比较总结:1.排序第5轮、比较1次,没有获得从小到大的排序 2.冒泡出了 2,由于还剩一个1,不用再比较了,至此通过5轮排序,完成整个排序。
通过以上五轮排序,若干次比较,我们有理由推断出一个结论:
对于一个长度为N的数组,我们需要排序 N-1 轮,每 i 轮 要比较 N-i 次。对此我们可以用双重循环语句,外层循环控制循环轮次,内层循环控制每轮的比较次数。
<?php
function getpao($arr)
{
$len=count($arr);
//设置一个空数组 用来接收冒出来的泡
//该层循环控制 需要冒泡的轮数
for($i=1;$i<$len;$i++)
{ //该层循环用来控制每轮 冒出一个数 需要比较的次数
for($k=0;$k<$len-$i;$k++)
{
if($arr[$k]>$arr[$k+1])
{
$tmp=$arr[$k+1];
$arr[$k+1]=$arr[$k];
$arr[$k]=$tmp;
}
}
}
return $arr;
}
$arr= array(6,3,8,2,9,1);
$res = getpao($arr);
print_r($res);
thinkphp5中.htaccess 的定义,通过这个模式,也适用于其他.htaccess定义
<IfModule mod_rewrite.c>
Options +FollowSymlinks -Multiviews
RewriteEngine On
#index.php/admin/users/index.html
RewriteRule ^(.*)list\.html$ $1/admin/users/index\.html
#index.php/admin/users/update/id/1.html
RewriteRule ^(.*)show_([0-9]+)\.html$ $1/admin/users/update/id/$2
#index.php/admin/users/index.html?page=2
RewriteRule ^(.*)p_([0-9]+)\.html$ $1/admin/users/index/page/$2
# http://127.0.0.1/tc/004_oop/tp5/public/p_2.html
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*)$ index.php/$1 [QSA,PT,L]
</IfModule>
tp5分页效果,中间数字化的设置。

核心分页默认文件的路径:tp5\thinkphp\library\think\paginator\driver\Bootstrap.php
/**
* 页码按钮
* @return string
*/
/*
protected function getLinks()
{
}
这个函数是我们要修改替换的!
我这里推荐一个:http://www.thinkphp.cn/code/3000.html
public $rollPage=1;//侧面显示个数
protected function getLinks()
{
if ($this->simple)
return '';
$block = [
'first' => null,
'slider' => null,
'last' => null
];
$side = $this->rollPage;
$window = $side * 2;
if ($this->lastPage < $window +1) {
$block['slider'] = $this->getUrlRange(1, $this->lastPage);
} elseif ($this->currentPage <= $window-1) {
$block['slider'] = $this->getUrlRange(1, $window + 1);
} elseif ($this->currentPage > ($this->lastPage - $window+1)) {
$block['slider'] = $this->getUrlRange($this->lastPage - ($window), $this->lastPage);
} else {
$block['slider'] = $this->getUrlRange($this->currentPage - $side, $this->currentPage + $side);
}
$html = '';
if (is_array($block['first'])) {
$html .= $this->getUrlLinks($block['first']);
}
if (is_array($block['slider'])) {
$html .= $this->getUrlLinks($block['slider']);
}
if (is_array($block['last'])) {
$html .= $this->getUrlLinks($block['last']);
}
return $html;
}
控制器中如何智能化设置呢?注意上面的:public $rollPage=1;//侧面显示个数
我们在控制器中的引用是这样的:
$list=$obj->where($tj)->paginate(2,false, [
‘query’ => Request::instance()->param(),//不丢失已存在的url参数
]);
$list->rollPage=2;//一定要放在$list->paginate 之后哦。这里就是重新对
分页栏每页显示的页数进行定义了。tp5分页效果 上一篇,下一篇的自定义修改。
![]()
核心分页默认文件的路径:tp5\thinkphp\library\think\paginator\driver\Bootstrap.php
对应的上一个方法名:
/**
* 上一页按钮
* @param string $text
* @return string
*/
protected function getPreviousButton($text = "«")
{
}
/**
* 下一页按钮
* @param string $text
* @return string
*/
protected function getNextButton($text = '»')
{
详细略
}
提示:你可以直接设置$text="默认值为上一篇/下一篇",但是这样就写死了,我们希望通过视图的方式直接修改上一篇或者下一篇的具体内容。
视图代码:
{$list->render("上一个","下一个")} ;//注意,默认这样传值是不对的,我们还需要按如下流程操作。在tp5\thinkphp\library\think\paginator\driver\Bootstrap.php 文件中
搜索: public function render()
修改:
public function render($a="",$b="")
{
if ($this->hasPages()) {
if ($this->simple) {
return sprintf(
'<ul class="pager">%s %s</ul>',
$this->getPreviousButton($a),
$this->getNextButton($b)
);
} else {
return sprintf(
'<ul class="pagination">%s %s %s</ul>',
$this->getPreviousButton($a),
$this->getLinks(),
$this->getNextButton($b)
);
}
}
}
php面向对象单例模式、工厂模式;面向对象三大基本特性与五大基本原则
一.单例模式
目的:为了控制对象的数量(只能够有一个,相当于类的计划生育)
做法:
1.在类里面做了一个公有的静态方法来造对象
2.将类的构造方法做成私有的;还要防止子类中重新定义构造方法,所以这里还要加final; final private function __construct(){}
3.防止clone,所以我们还需要定义一个final private function __clone(){}
class Ren
{
public $name;
static public $dx; //静态成员变量用来存储该对象
final private function __construct() //把构造函数设置为私有,类的外部就不能用new造对象了
{
}
final private function __clone() //防止clone复制对象
{
}
static function DuiXiang() //做一个静态的方法,用来在类的内部造对象
{
if(empty(self::$dx)) //判断上面定义的变量是否有值,如果没有,就造一个对象,如果有,就直接输出这个
{
self::$dx = new Ren(); //因为是静态变量,只能用类名调用
}
return self::$dx;
}
}$r = Ren::DuiXiang();
$r->name = "张三";
$r1 = Ren::DuiXiang();
$r1->name = "李四";
var_dump($r); //由于上面已经造了一个对象$r,所以当再造$r1时,$r1跟$r是一样的对象二、工厂模式
工厂模式的最大优点在于创建对象上面,就是把创建对象的过程封装起来,这样随时可以产生一个新的对象。
减少代码进行复制粘帖,耦合关系重,牵一发动其他部分代码。
通俗的说,以前创建一个对象要使用new,现在把这个过程封装起来了。
假设不使用工厂模式:那么很多地方调用类a,代码就会这样子创建一个实例:new a(),假设某天需要把a类的名称修改,意味着很多调用的代码都要修改。
工厂模式的优点就在创建对象上。
工厂模式的优点就在创建对象上。建立一个工厂(一个函数或一个类方法)来制造新的对象,它的任务就是把对象的创建过程都封装起来,
创建对象不是使用new的形式了。而是定义一个方法,用于创建对象实例。
abstract class YunSuan
{
public $a;
public $b;
function Suan(){}
}
class Jia extends YunSuan
{
function Suan(){
return $this->a+$this->b;
}
}
class Jian extends YunSuan
{
function Suan(){
return $this->a-$this->b;
}
}
class Cheng extends YunSuan{
function Suan(){
return $this->a*$this->b;
}
}
//做一个工厂类
class GongChang{
static function ShengChan($fuhao){
if($fuhao=="+"){
return new Jia();
}else if($fuhao=="*"){
return new Cheng();
}
}
}
//算加法
$suan = GongChang::ShengChan("+");
$suan->a = 10;
$suan->b = 5;
echo $suan->Suan();
静态方法可以调静态变量,但不能调普通变量
普通方法可以调静态变量,也可以普通变量

面向对象三大基本特性与五大基本原则
三大特性是:封装、继承、多态
所谓封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
封装是面向对象的特征之一,是对象和类概念的主要特性。 简单的说,一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分。
所谓继承是指可以让某个类型的对象获得另一个类型的对象的属性的方法,它支持按级分类的概念。
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
所谓多态就是指一个类实例的相同方法在不同情形有不同表现形式。
多态是面向对象的三大特性中除封装和继承之外的另一重要特性。它展现了动态绑定的功能,也称为“同名异式”。多态的功能可让软件在开发和维护时,达到充分的延伸性。事实上,多态最直接的定义是让具有继承关系的不同类对象,可以对相同名称的成员函数调用,产生不同反应效果。【多态性概念】所谓多态性就是指一段程序能够处理多种类型对象的能力。在PHP中,多态一般情况可以理解就是方法的重写【很多资料都是这么解释的,虽然这样不是很严禁!因为php不具有像java那种清晰的多态】。方法重写是指一个子类中可以重新修改父类中的某些方法,使其具有自己的特征。重写要求子类的方法和父类的方法名称相同,这可以通过声明抽象类或是接口来规范。
多态的好处:大大提高程序的扩展,增强系统的灵活性,降低模块间的耦合。
虽然php不具有像java那种清晰的多态;但是严禁上说可以通过编程逻辑实现多态,如下:php体现现了多态。
<?php
abstract class animal{
abstract function fun();
}
class cat extends animal{
function fun(){
echo "cat say miaomiao...";
}
}
class dog extends animal{
function fun(){
echo "dog say wangwang...";
}
}
function work($obj){
if($obj instanceof animal){
$obj -> fun();
}else{
echo "no function";
}
}
work(new dog());
work(new cat());
上面通过一个关键字instanceof来判断,变量指向的对象是否是animal类的一个实例,下面new cat(),new dog()都是animal子类的对象,而输出了“dog say wangwang…”和“cat say miaomiao…”,说明子类对象是父类的一个实例,从而达到了java多态的功能。
上边的类是抽象类,也表明了接口与实现接口的类对象同样可以适用。
至此,得出php虽然多态体现模糊,但还是具有多态特性的。
PHP5中实现多态的两种方法实例分享 https://www.jb51.net/article/49184.htm 浅谈多态以及php的实现方法 https://blog.csdn.net/whd526/article/details/70242918 重载不应归在多态的范畴内 https://blog.csdn.net/whd526/article/details/70240684 方法重写与方法重载的区别 https://www.cnblogs.com/zheting/p/7751787.html 重写: 类的继承关系可以产生一个子类,子类继承父类,它具备了父类所有的特征, 继承了父类所有的方法和变量。 子类可以定义新的特征,当子类需要修改父类的一些方法进行扩展,增大功能, 程序设计者常常把这样的一种操作方法称为重写,也叫称为覆写或覆盖。 重载: 方法重载是让类以统一的方式处理不同类型数据的一种手段。 调用方法时通过传递给它们的不同个数和类型的参数来决定具体使用哪个方法, 这就是多态性。 提示:因为php是弱类型语言,一个类中它也不允许定义相同方法名。 所以针对php,很多资料都把重写和重载看成一个概念【重写】。
五大基本原则
1、单一职责原则SRP(Single Responsibility Principle)
是指一个类的功能要单一,不能包罗万象。如同一个人一样,分配的工作不能太多,否则一天到晚虽然忙忙碌碌的,但效率却高不起来。
2、开放封闭原则OCP(Open-Close Principle)
一个模块在扩展性方面应该是开放的而在更改性方面应该是封闭的。比如:一个网络模块,原来只服务端功能,而现在要加入客户端功能,
那么应当在不用修改服务端功能代码的前提下,就能够增加客户端功能的实现代码,这要求在设计之初,就应当将服务端和客户端分开,公共部分抽象出来。
3、替换原则(the Liskov Substitution Principle LSP)
子类应当可以替换父类并出现在父类能够出现的任何地方。比如:公司搞年度晚会,所有员工可以参加抽奖,那么不管是老员工还是新员工,
也不管是总部员工还是外派员工,都应当可以参加抽奖,否则这公司就不和谐了。
使用里氏替换原则时需要注意,子类的所有方法必须在父类中声明,或子类必须实现父类中声明的所有方法。尽量把父类设计为抽象类或者接口,让子类继承父类或实现父接口,并实现在父类中声明的方法,运行时,子类实例替换父类实例,我们可以很方便地扩展系统的功能。
里氏替换原则是对类继承的一种约束。对里氏替换原则有两种理解:
1. 不能随便去继承不合适的,有多余方法或者属性的类。
2. 子类可以扩展父类的功能,但不能改变父类原有的功能。
4、依赖(倒置)原则(the Dependency Inversion Principle DIP) 具体依赖抽象,上层依赖下层。依赖倒置原则核心一句话:面向接口编程。
“依赖倒置是一种软件设计思想,在传统软件中,上层代码依赖于下层代码,当下层代码有所改动时,上层代码也要相应进行改动,因此维护成本较高。而依赖倒置原则的思想是,上层不应该依赖下层,应依赖接口。意为上层【汽车】代码定义接口,下层代码实现该接口,从而使得下层【具体汽车如宝马,奔驰】依赖于上层接口,降低耦合度,提高系统弹性”。
耦合性也叫块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块之间越独立则越差,模块间耦合的高低取决于模块间接口的复杂性,调用的方式以及传递的信息。
形象的说,就是要将代码写的和电脑一样,主类就是电脑的主机箱,当程序需要实现什么功能的时候只需要在其他的类引入接口,就像电脑上的usb接口。
<?php
// 司机开奔驰,未用依赖倒置原则的写法
class Benz{
public function run(){
return " Benz is runing!!!";
}
}
class Driver{
public function drive(Benz $car){
echo $car -> run();
}
}
class Client{
public static function doing(){
$driver = new Driver();
$driver -> drive( new Benz() );
}
}
Client :: doing();
// 那么如果司机想开宝马呢?,是不是就要修改Driver了,这就违反了开闭原则了,怎么能只在Client添加代码就让宝马车也会开呢?
interface ICar{
//定义一个汽车接口
public function run();
}
class BMW implements ICar{
public function run(){
return "BMW is runing !!!";
}
}
class Benz implements ICar{
public function run(){
return "Benz is runing !!!";
}
}
interface IDriver{
//定义一个司机接口,以防以后有A照,B照,C照的
public function drive(ICar $car);
}
class Driver implements IDriver{
public function drive(ICar $car){
echo "<br>" . $car -> run();
}
}
class Client{
public static function doing(){
$driver = new Driver();
$driver -> drive( new BMW() ); //开宝马
$driver -> drive( new Benz() ); //开奔驰
.
.
.
.
}
}
Client :: doing();
?>
案例解释二:
比如有这么个需求,用户注册完成后要发送一封邮件,然后你有如下代码:
先有邮件类'Email.class.php'
class Mail{
public function send()
{
/*这里是如何发送邮件的代码*/
}
}
然后又注册的类'Register.class.php'
class Register{
private $_emailObj;
public function doRegister()
{
/*这里是如何注册*/
$this->_emailObj = new Mail();
$this->_emailObj->send();//发送邮件
}
}
然后开始注册:
include 'Mail.class.php';
include 'Register.class.php';
$reg = new Register();
$reg->doRegister();
看起来事情很简单,你很快把这个功能上线了,看起来相安无事... xxx天过后,产品人员说发送邮件的不好,要使用发送短信的,然后你说这简单我把'Mail'类改下...
又过了几天,产品人员说发送短信费用太高,还是改用邮件的好... 此时心中一万个草泥马奔腾而过...
这种事情,常常在产品狗身上发生,无可奈何花落去...
以上场景的问题在于,你每次不得不对'Mail'类进行修改,代码复用性很低,高层过度依赖于底层。那么我们就考虑'依赖倒置原则',让底层继承高层制定的接口,高层依赖于接口。
interface Mail
{
public function send();
}
class Email implements Mail()
{
public function send()
{
//发送Email
}
}
class SmsMail implements Mail()
{
public function send()
{
//发送短信
}
}
class Register
{
private $_mailObj;
public function __construct(Mail $mailObj)
{
$this->_mailObj = $mailObj;
}
public function doRegister()
{
/*这里是如何注册*/
$this->_mailObj->send();//发送信息
}
}
下面开始发送信息
/* 此处省略若干行 */
$reg = new Register();
$emailObj = new Email();
$smsObj = new SmsMail();
$reg->doRegister($emailObj);//使用email发送
$reg->doRegister($smsObj);//使用短信发送
/* 你甚至可以发完邮件再发短信 */
上面的代码解决了'Register'对信息发送类的依赖,使用构造函数注入的方法,使得它只依赖于发送短信的接口,只要实现其接口中的'send'方法,不管你怎么发送都可以。上例就使用了"注入"这个思想,就像注射器一样将一个类的实例注入到另一个类的实例中去,需要用什么就注入什么。当然"依赖倒置原则"也始终贯彻在里面。"注入"不仅可以通过构造函数注入,也可以通过属性注入,上面你可以可以通过一个"setter"来动态为"mailObj"这个属性赋值。
https://www.cnblogs.com/painsOnline/p/5138806.html
5、接口分离原则(the Interface Segregation Principle ISP)
模块间要通过抽象接口隔离开,而不是通过具体的类强耦合起来
PHP中对象的深拷贝与浅拷贝
先说一下深拷贝和浅拷贝通俗理解
深拷贝:赋值时值完全复制,完全的copy,对其中一个作出改变,不会影响另一个
浅拷贝:赋值时,引用赋值,相当于取了一个别名。对其中一个修改,会影响另一个
PHP中, = 赋值时,普通对象是深拷贝,但对对象来说,是浅拷贝。也就是说,对象的赋值是引用赋值。(对象作为参数传递时,也是引用传递,无论函数定义时参数前面是否有&符号)
php4中,对象的 = 赋值是实现一份副本,这样存在很多问题,在不知不觉中我们可能会拷贝很多份副本。
php5中,对象的 = 赋值和传递都是引用。要想实现拷贝副本,php提供了clone函数实现。
clone完全copy了一份副本。但是clone时,我们可能不希望copy源对象的所有内容,那我们可以利用__clone来操作。
在__clone()中,我们可以进行一些操作。注意,这些操作,也就是__clone函数是作用于拷贝的副本对象上的
<?php
//普通对象赋值,深拷贝,完全值复制
$m = 1;
$n = $m;
$n = 2;
echo $m;//值复制,对新对象的改变不会对m作出改变,输出 1.深拷贝
echo PHP_EOL;
/*==================*/
//对象赋值,浅拷贝,引用赋值
class Test{
public $a=1;
}
$m = new Test();
$n = $m;//引用赋值
$m->a = 2;//修改m,n也随之改变
echo $n->a;//输出2,浅拷贝
echo PHP_EOL;
?>由于对象的赋值时引用,要想实现值复制,php提供了clone函数来实现复制对象。
但是clone函数存在这么一个问题,克隆对象时,原对象的普通属性能值复制,但是源对象的对象属性赋值时还是引用赋值,浅拷贝。
<?php
class Test{
public $a=1;
}
class TestOne{
public $b=1;
public $obj;
//包含了一个对象属性,clone时,它会是浅拷贝
public function __construct(){
$this->obj = new Test();
}
}
$m = new TestOne();
$n = $m;//这是完全的浅拷贝,无论普通属性还是对象属性
$p = clone $m;
//普通属性实现了深拷贝,改变普通属性b,不会对源对象有影响
$p->b = 2;
echo $m->b;//输出原来的1
echo PHP_EOL;
//对象属性是浅拷贝,改变对象属性中的a,源对象m中的对象属性中a也改变
$p->obj->a = 3;
echo $m->obj->a;//输出3,随新对象改变
?>要想实现对象真正的深拷贝,有下面两种方法:
写clone函数:如下
<?php
class Test{
public $a=1;
}
class TestOne{
public $b=1;
public $obj;
//包含了一个对象属性,clone时,它会是浅拷贝
public function __construct(){
$this->obj = new Test();
}
//方法一:重写clone函数
public function __clone(){
$this->obj = clone $this->obj;
}
}
$m = new TestOne();
$n = clone $m;
$n->b = 2;
echo $m->b;//输出原来的1
echo PHP_EOL;
//可以看到,普通属性实现了深拷贝,改变普通属性b,不会对源对象有影响
//由于改写了clone函数,现在对象属性也实现了真正的深拷贝,对新对象的改变,不会影响源对象
$n->obj->a = 3;
echo $m->obj->a;//输出1,不随新对象改变,还是保持了原来的属性
?>改写__clone()函数不太方便,而且你得在每个类中把这个类里面的对象属性都在__clone()中 一一 clone
第二种方法,利用序列化反序列化实现,这种方法实现对象的深拷贝简单,不需要修改类。
<?php
class Test{
public $a=1;
}
class TestOne{
public $b=1;
public $obj;
//包含了一个对象属性,clone时,它会是浅拷贝
public function __construct(){
$this->obj = new Test();
}
}
$m = new TestOne();
//方法二,序列化反序列化实现对象深拷贝
$n = serialize($m);
$n = unserialize($n);
$n->b = 2;
echo $m->b;//输出原来的1
echo PHP_EOL;
//可以看到,普通属性实现了深拷贝,改变普通属性b,不会对源对象有影响
$n->obj->a = 3;
echo $m->obj->a;//输出1,不随新对象改变,还是保持了原来的属性,可以看到,序列化和反序列化可以实现对象的深拷贝
?>还有第三种方法,其实和第二种类似,json_encode之后再json_decode,实现赋值
smarty笔记-徐老师,xuduowei,徐多蔚,合肥php老师
<?php
include_once("libs/Smarty.class.php"); //包含smarty类文件
$smarty = new Smarty(); //建立smarty实例对象$smarty
//$smarty->config_dir="libs/Config_File.class.php"; // 目录变量,新版本可以去掉。老版本也可以去掉
$smarty->caching=false; //是否使用缓存,项目在调试期间,不建议启用缓存
$smarty->cache_lifetime = 20;
$smarty->template_dir = "./templates"; //设置模板目录
$smarty->compile_dir = "./templates_c"; //设置编译目录
$smarty->cache_dir = "./smarty_cache"; //缓存文件夹
//----------------------------------------------------
//左右边界符,默认为{},但实际应用当中容易与JavaScript相冲突
//----------------------------------------------------
$smarty->left_delimiter = "{";
$smarty->right_delimiter = "}";
?>
笔记:
smarty是一款基于php面向对象编程基础上开发的框架系统【模板引擎框架】
官方网址:smarty.net
基于smarty开发的一款非常经典的程序项目:www.phpyun.com【大型人才招聘系统】
smarty的目的:使得php程序和美工分离!
特点:
1、速度快!
2、缓存技术;【页面缓存】
3、编译!!!就是把视图中的标签替换成php。
如何配置smarty?
配置参考xdw.php
===========================
如何设置模板变量?$smarty->assign(“title”,$name);
其中 title就是模板变量
如何渲染模板?$smarty->display(“1.0.htm”);
模板中又该如何调用模板变量呢?
{$title}
注意:$不能少,{}边界付不能少!
{} 在配置文件中进行了定义!
{}和我们的js中的函数主体冲突!解决方法是:
{literal}
js
{/literal}
==============================================
模板中,标签的值的传递【模板方法的应用!】
模板方法的应用:
{$name|substr:’1′:’2′}
若我们需要自定义函数。则可以再配置文件中定义!
===========================================方案一:
第一步:
xdw.php
function abc($arr){ //这个参数是一个数组。
print_r($arr[‘con2’]);
}
中设置好函数;
第二步:在php页面中,如1.0.php中注册模板函数!
$smarty->register_function(“abc1″,”abc”);
视图中调用的方式如下:
{函数名 con=$title}
{abc1 con=$title con2=2 con3=3}
function abc($arr){ //这个参数是一个数组。
$arr[‘con’]
}
=========================================方案二:
到smarty核心文件夹下的plugins文件夹创建一个名为
function.xxx.php的文件。注意:xxx可以自定义。
如:xxx为xdw function.xdw.php文件
code:
<?php
function smarty_function_xdw($c, &$smarty){
return $c[‘con’];
}
?>
模板中的引用:
{函数名 con=666}
{xdw con=666}
提示:方案二定义的函数在模板中可直接被调用,不需要在控制器中注册。因为方案二中的函数都被默认注册了。
==================================================
smarty中数组值的传递和显示。
PHP:
$arr=array(“张三”,”李四”,”王五”);
$smarty->assign(“arr”,$arr);
HTML:
{foreach from=$arr item=t}
{$t}
{/foreach}
二维数组!
若定义的时候是键名=>值的方式定义!
则html中引用的时候按如下格式:
{foreach from=$arr item=t}
{$t.name} 提示若{$t[‘name’]}就报错了。
{/foreach}
{foreach key=i from=$arr item=t}
{$t.name}——-{$i}
{/foreach}
文件的包含!
{include file=”head.htm”}
{php}
php代码。
{/php}
WordPress 代码高亮插件:Pure-Highlightjs(支持可视化下插入代码)
Pure-Highlightjs 一个基于 Highlightjs 实现的 WordPress 代码高亮插件,支持 N 多种语言高亮,还提供多种主题。支持在 WordPress 可视化编辑模式下插入代码。
Pure-Highlightjs 依赖于以下开源项目:
highlight.js https://highlightjs.org
highlight.js 是一个用于在任何 web 页面上着色显示各种示例源代码语法的 JS 项目
安装说明
1. 下载
点击下载 https://github.com/icodechef/…/Pure-Highlightjs_1.0.zip
2. 安装
进入 WordPress 后台管理页面,“插件 》安装插件 》上传插件”,上传刚才下载的 ZIP 文件,然后安装。
或者解压安装包,上传到插件目录,/wp-content/plugins/。
3. 启用
安装完毕后,在已经安装的插件里启用 “Pure Highlightjs”。
如何使用
可直接在可视化编辑界面点击“插入代码”按钮,然后选择代码类型,粘贴代码插入即可:
GitHub 地址:Pure-Highlightjs
PHP设计模式-单例模式
单例模式(Singleton Pattern 单件模式或单元素模式)
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
单例模式是一种常见的设计模式,在计算机系统中,线程池、缓存、日志对象、对话框、打印机、数据库操作、显卡的驱动程序常被设计成单例。
单例模式分3种:懒汉式单例、饿汉式单例、登记式单例。
单例模式有以下3个特点:
1.只能有一个实例。
2.必须自行创建这个实例。
3.必须给其他对象提供这一实例。
那么为什么要使用PHP单例模式?
PHP一个主要应用场合就是应用程序与数据库打交道的场景,在一个应用中会存在大量的数据库操作,针对数据库句柄连接数据库的行为,使用单例模式可以避免大量的new操作。因为每一次new操作都会消耗系统和内存的资源。
在以往的项目开发中,没使用单例模式前的情况如下:
//初始化一个数据库句柄
$db = new DB(...);
//比如有个应用场景是添加一条用户信息
$db->addUserInfo();
......
//然而我们要在另一地方使用这个用户信息,这时要用到数据库句柄资源,可能会这么做
......
function test() {
$db = new DB(...);
$db->getUserInfo();
......
有些朋友也许会说,可以直接使用global关键字!
global $db;
......
的确global可以解决问题,也起到单例模式的作用,但在OOP中,我们拒绝这种编码。因为global存在安全隐患(全局变量不受保护的本质)。
全局变量是面向对象程序员遇到的引发BUG的主要原因之一。这是因为全局变量将类捆绑于特定的环境,破坏了封装。如果新的应用程序无法保证一开始就定义了相同的全局变量,那么一个依赖于全局变量的类就无法从一个应用程序中提取出来并应用到新应用程序中。
确切的讲,单例模式恰恰是对全局变量的一种改进,避免那些存储唯一实例的全局变量污染命名空间。你无法用错误类型的数据覆写一个单例。这种保护在不支持命名空间的PHP版本里尤其重要。因为在PHP中命名冲突会在编译时被捕获,并使脚本停止运行。
PHP单例模式实例:
先看图:

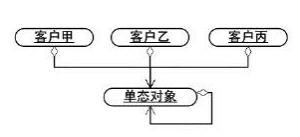
上面的对象图中,有一个“单例对象”,而“客户甲”、“客户乙”和“客户丙”是单例对象的三个客户对象。可以看到,所有的客户对象共享一个单例对象。而且从单例对象到自身的连接线可以看出,单例对象持有对自己的引用。
<?php class User { //静态变量保存全局实例 static private $_instance=null; //私有构造函数,防止外界实例化对象 private function __construct() { echo "构造了"; } //私有克隆函数,防止外办克隆对象 private function __clone() { } //静态方法,单例统一访问入口 //用于访问类的实例的公共的静态方法 static public function getInstance(){ if(!(self::$_instance instanceof User)){ echo "实例化<br>"; self::$_instance = new self; } return self::$_instance; } public function getName() { echo "hello world!"; } } $obj=User::getInstance(); $obj->getName(); $obj2=User::getInstance(); $obj2->getName(); ?>
单例模式的优缺点:
优点:
1. 改进系统的设计
2. 是对全局变量的一种改进
缺点:
1. 难于调试
2. 隐藏的依赖关系
3. 无法用错误类型的数据覆写一个单例