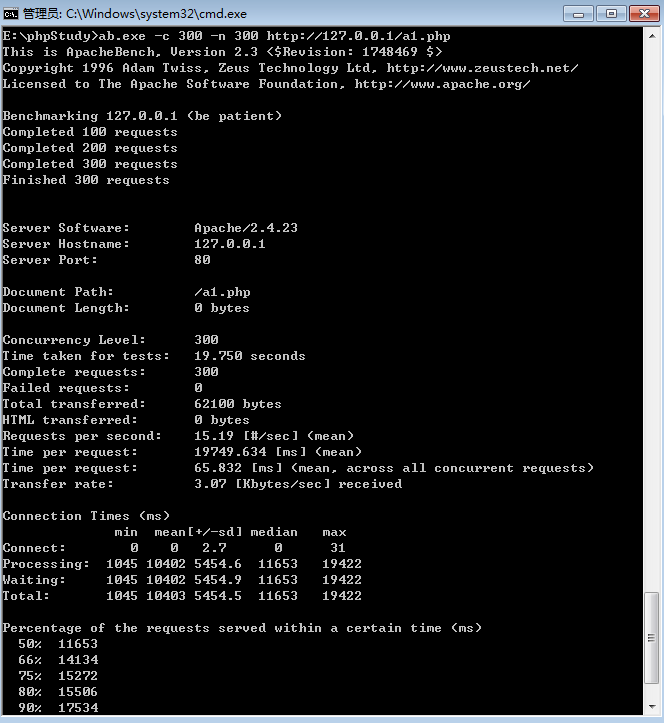
模拟准备–如何模拟高并发访问一个脚本:apache安装文件的bin/ab.exe可以模拟并发量 -c 模拟多少并发量 -n 一共请求多少次 http://请求的脚本
例如:cmd: apache安装路径/bin/ab.exe -c 10 -n 10 http://web.test.com/test.php
【切入正题】
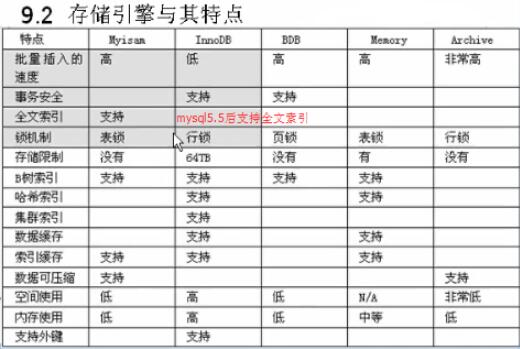
MYSQL中的锁:
语法 :
LOCK TABLE 表名1 READ|WRITE, 表名2 READ|WRITE ……………… 【锁表】
UNLOCK TABLES 【释放表】
Read:读锁|共享锁 : 所有的客户端只能读这个表不能写这个表
Write:写锁|排它锁: 所有当前锁定客户端可以操作这个表,其他客户端只能阻塞
注意:在锁表的过程中只能操作被锁定的表,如果要操作其他表,必须把所有要操作的表都锁定起来!
PHP中的文件锁 (锁的是文件,不是表)
文件锁的文件与表有什么关系?:一点关系也没有,与令牌相似,谁拿到谁操作。所以表根本没锁。
测试时,有个文件就行,叫什么名无所谓。
总结:
项目中应该只使用PHP中的文件锁,尽量避免锁表,因为如果表被锁定了,那么整个网站中所有和这个表相关的功能都被拖慢了(例如:前台很多用户一直下订单,商品表mysql锁表,其他与商品表相关的操作一直处于阻塞状态【读不出来商品表】,因为一个功能把整个网站速度拖慢)。
我的一个项目就是O2O外卖,中午12-2点,晚上6点都是订单高并发时,这种情况下,MySQL锁显然是不考虑的,用户体验太差。其实根据实际的需求,外卖可以不用设计库存量的,当然除了秒杀活动模块还是需要php文件锁的。
应用场景:
1. 高并发下单时,减库存量时要加锁
2. 高并发抢单、抢票时要使用
MySQL锁示例代码:
<?php
/**
模拟秒杀活动-- 商品100件
CREATE TABLE a
(
id int comment '模拟100件活动商品的数量'
);
INSERT INTO a VALUES(100);
模仿:以10的并发量访问这个脚本! 使用apache自带的ab.exe软件
*/
error_reporting(0);
mysql_connect('localhost','root','admin123');
mysql_select_db('test');
# mysql 锁
mysql_query('LOCK TABLE a WRITE');// 只有一个客户端可以锁定表,其他客户端阻塞在这
$rs = mysql_query('SELECT id FROM a');
$id = mysql_result($rs, 0, 0);
if($id > 0)
{
--$id;
mysql_query('UPDATE a SET id='.$id);
}
# mysql 解锁
mysql_query('UNLOCK TABLES');
PHP文件锁示例代码:
<?php
/**
模拟秒杀活动-- 商品100件
CREATE TABLE a
(
id int comment '模拟100件活动商品的数量'
);
INSERT INTO a VALUES(100);
模仿:以10的并发量访问这个脚本! 使用apache自带的ab.exe软件
*/
error_reporting(0);
mysql_connect('localhost','root','admin123');
mysql_select_db('test');
# php中的文件锁
$fp = fopen('./a.lock', 'r'); // php的文件锁和表没关系,随便一个文件即可
flock($fp, LOCK_EX);// 排他锁
$rs = mysql_query('SELECT id FROM a');
$id = mysql_result($rs, 0, 0);
if($id > 0)
{
--$id;
mysql_query('UPDATE a SET id='.$id);
}
# php的文件锁,释放锁
flock($fp, LOCK_UN);
fclose($fp);
其实还有一种最简单的方案,一个sql就可以解决这个事情。
@$mysql = mysql_connect('localhost','root','');
mysql_query('set names utf8');
mysql_select_db('test');
mysql_query('UPDATE warehouse SET `stock` = `stock` -1 WHERE `stock` > 0'); //可以避免库存为负数
测试的方法是,找到Apache下的ab.exe,拖入CMD终端,然后输入指定参数测试。
具体参数说明Google一下你就知道,比如耗时之类的…这里不做详细说明。
其他参考:
php mysql 锁表和解锁详细语句http://blog.sina.com.cn/s/blog_6e637ea701016r01.html
mysql锁(行锁,表锁)同一用户同一秒操作保持唯一性https://blog.csdn.net/webnoties/article/details/22874431
MySQL锁机制和PHP锁机制 http://phpkim.iteye.com/blog/2294464
Mysql的锁机制与PHP文件锁处理高并发简单思路https://www.cnblogs.com/yuandongdong/p/7560327.html